1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import jieba
txt = open ("红楼梦.txt","r", encoding="ANSI").read()
words = jieba.lcut(txt)
excludes ={"一声","媳妇","不用","人家","妹妹","看见","问道","如何","二爷","屋里","丫头","小丫头","听说","什么","一个","我们","那里","如今","你们","说道","知道","起来","姑娘","这里","出来","他们","众人","自己","进来","这样","听见","这个","不知","不是","没有","两个","怎么","只见","自己","一面","大家","只是","回来","就是","东西","咱们","告诉","所以","出去","不敢","这些","只得","不好","的话","不过","一时","姐姐","太太","奶奶","过来","不能","心里","老爷","二人","银子","今日","如此","还有","几个","答应","这么","说话","只管","一回","那边","这话","外头","打发","自然","今儿","罢了","那些"}
counts={}
for word in words:
if len(word)==1:
continue
elif word == "宝玉":
rword = "贾宝玉"
elif word =="凤姐" or word =="凤姐儿":
rword = "王熙凤"
elif word == "老太太":
rword ="贾母"
elif word =="宝钗":
rword = "薛宝钗"
elif word =="探春":
rword ="贾探春"
elif word =="湘云":
rword ="史湘云"
elif word =="黛玉":
rword ="林黛玉"
else:
rword =word
counts[rword]=counts.get(rword,0)+1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key = lambda x:x[1],reverse =True)
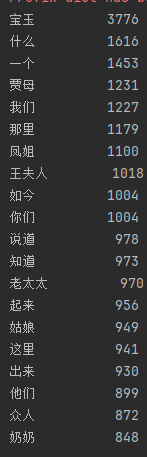
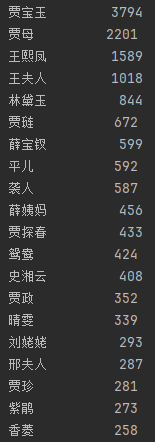
for i in range(20):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
|