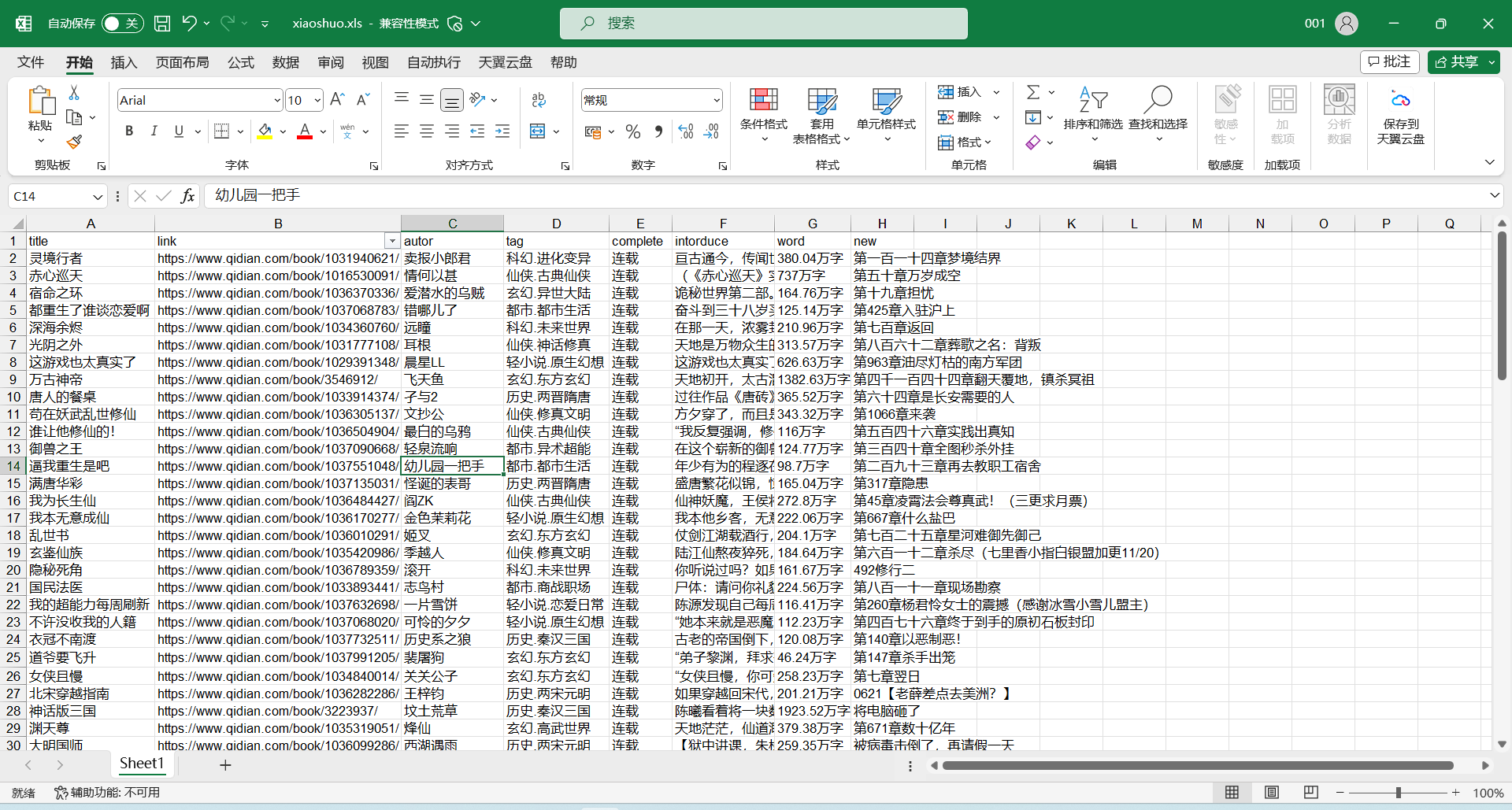
if __name__=='__main__': # 主页链接 urls=['https://www.qidian.com/all/page'+str(i) for i inrange(1,6)] for url in urls: get(url,index) index+=20# 计数 # excel表头 header=['title','link','autor','tag','complete','intorduce','word','new'] #创建表格 book=xlwt.Workbook(encoding='utf-8') sheet = book.add_sheet('Sheet1') for h inrange(len(header)): # 写入表头 sheet.write(0, h, header[h])
i = 1# 行数 forlistin all_info_list: j = 0# 列数 # 写入爬虫数据 for data inlist: sheet.write(i, j, data) j += 1 i += 1 # 保存文件 book.save('xiaoshuo.xls')